Cloud platforms make it remarkably easy to launch something useful. In a short space of time, a team can publish an API, expose a web application, attach a public IP address, open a storage endpoint, or place a load balancer in front of a new service. That speed is one of the great strengths of cloud adoption. It is also one of the reasons businesses can underestimate how quickly their external exposure grows.

A common misunderstanding appears early in many cloud journeys. A business assumes that because the service is running on a well-known provider, the service is broadly secure by default. In reality, the provider usually protects the underlying platform and physical infrastructure far better than most individual customers could do on their own. That does not mean the customer''s own public exposure is automatically safe. It means the responsibility is divided, and the part most visible to attackers often remains the customer''s problem.
Cloud providers protect the platform, not every decision you make on top of it
This is where the shared-responsibility model matters. Major cloud providers are explicit about the fact that they secure the infrastructure they operate, while customers remain responsible for the way their own services, identities, data paths, network controls, and public endpoints are configured. The cloud provider may secure the hardware, the virtualization layer, the physical facilities, and large parts of the managed service platform. But if a business publishes an endpoint too broadly, stores data with excessive public reachability, or leaves administrative access more open than intended, the provider has not removed that risk.
This distinction matters because attackers do not usually begin by asking whether your provider is reputable. They begin by asking what they can reach. If a service is internet-facing, it becomes part of your attack surface regardless of whether it runs in your own rack, in a private datacentre cage, or on the infrastructure of AWS, Azure, Google Cloud, or another major platform.
Public cloud services are easy to create and easy to expose
Modern cloud platforms are designed to help teams publish services quickly. A few clicks can create a public API endpoint, a globally reachable application entry point, or a storage service that is reachable well beyond the audience originally intended. That convenience is useful for the business, but it also means exposure can appear faster than review processes can keep up with it.
An organisation may create a public API because a mobile application or partner integration needs it. Another team may deploy an internet-facing load balancer because it is the fastest path to putting a web service into production. A storage bucket may be used for static content, backups, exported data, or public website assets. None of these decisions is inherently wrong. The problem starts when the reachability is wider than expected, the access rules are weaker than they should be, or the deployment moves into production without anyone stepping back to review what is now visible from the public internet.
Default settings are not the same as safe design
One of the most dangerous assumptions in cloud environments is that a default or out-of-the-box setup is equivalent to a production-ready security posture. Defaults are usually designed to help customers get started, not to make every architecture decision on their behalf. In some cases the defaults are now safer than they were in the past. In many cases, however, a secure outcome still depends on how the customer configures identity, network access, storage policy, origin restrictions, transport security, logging, and exposure boundaries.
That gap is where many weaknesses appear. A service may be reachable from the internet when it was meant for a smaller trusted audience. A bucket may not be fully public, but policy combinations may still expose content more broadly than the business expects. A load balancer may be intentionally public, but the systems behind it may reveal alternate ports, management paths, or debugging endpoints. An API may be published correctly for one consumer and still be missing the protective controls that matter once the wider internet starts interacting with it.
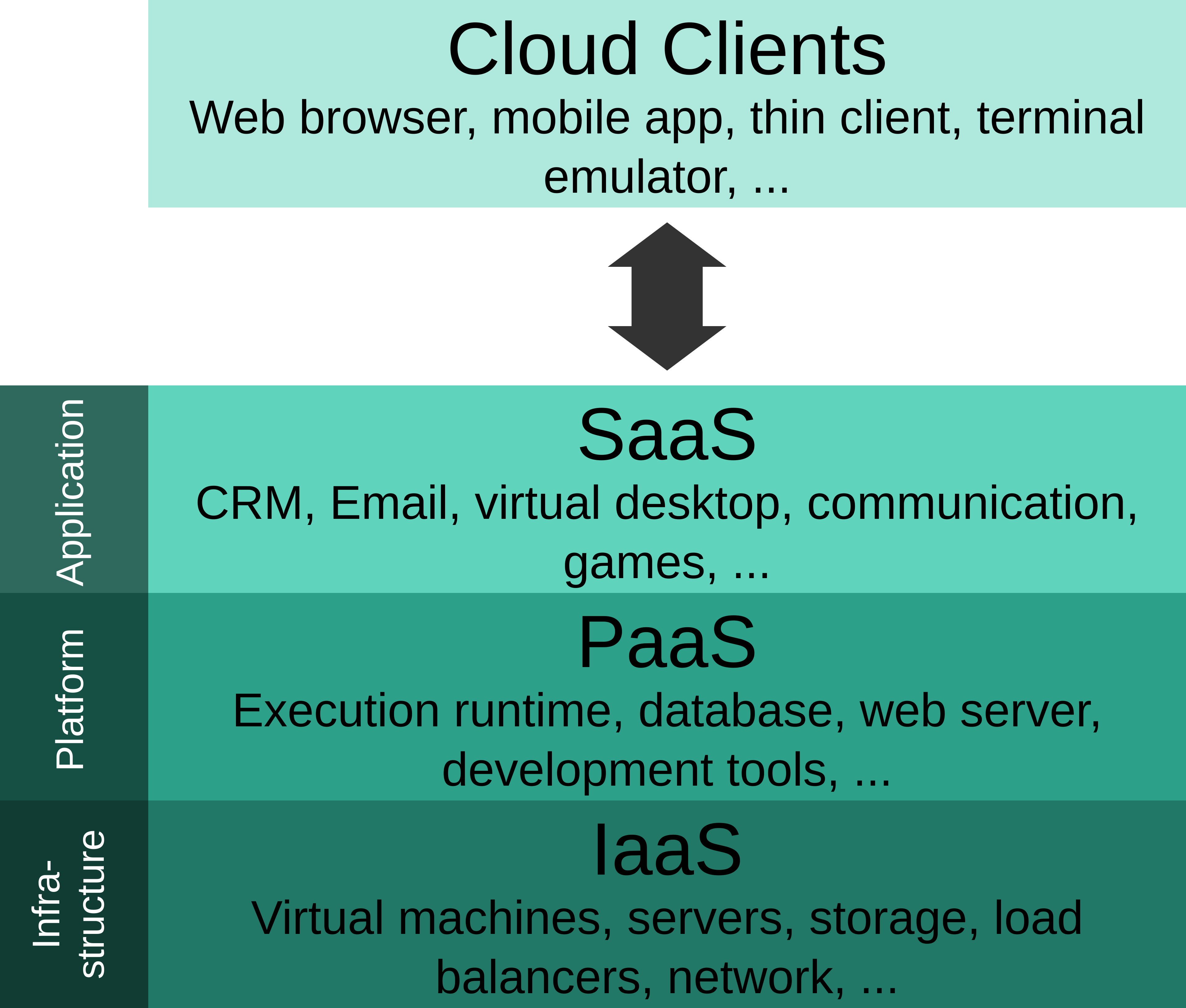
Examples that regularly create risk in cloud environments
Public API endpoints are a common example. Services such as Amazon API Gateway, Azure-hosted APIs, and cloud-native web applications make it easy to publish interfaces for customers and partners. But the security questions do not stop once the endpoint is live. Authentication, rate limiting, error handling, origin restrictions, transport security, and the visibility of underlying services all become part of the real exposure picture.
Storage is another area where convenience can create confusion. Teams may intentionally publish files, static content, or software artifacts, then later forget that the same storage layer also contains sensitive or internal material. Public access settings, inherited permissions, object URLs, and account-level controls all matter. The platform offers the capability, but the safe use of that capability still depends on the customer.
Load balancers and public IP addresses create a similar challenge. They are essential for many legitimate architectures, especially customer-facing applications. But once a public frontend exists, it becomes important to understand exactly what is behind it, which ports respond, which hostnames point to it, what alternate services exist on the same address, and whether the surrounding controls are really limited to the paths the business intends to expose.
Even hosted websites deserve the same scrutiny. A business may assume that because a site is behind a cloud platform, the hard part has been solved. In practice, hosted applications can still disclose misconfigured headers, weak origin design, exposed administration paths, risky service combinations, or supporting infrastructure that is reachable more broadly than expected. Cloud hosting changes where the service runs. It does not remove the need to review what the service looks like from the outside.
The problem is often not negligence but missing specialist review
Many businesses using cloud services do not have a dedicated network security engineer or a mature security engineering team reviewing every public deployment. That is especially common in growing companies, product teams, and organisations where infrastructure responsibility is spread across operations, development, and platform roles. Cloud tools make deployment easier, but they also make it easier for exposure decisions to be made by people whose main focus is delivery rather than external security posture.
This does not mean those teams are careless. It usually means they are busy, pragmatic, and trying to move quickly. The provider has already handled a large part of the infrastructure burden, so it is natural to assume that the environment is mostly safe. The remaining risks are easy to miss because they often sit in the boundary between application delivery and security engineering. They are visible from the internet, but they are not always visible from the deployment checklist.
Why external visibility matters in cloud deployments
Cloud environments change quickly. A team adds a new public endpoint for a launch, connects another domain, enables a temporary access path for testing, or puts a service behind a public frontend to solve a delivery problem. Weeks later, the business still sees the service as a normal part of the platform, but attackers only see a reachable target.
That is why external visibility matters so much. Businesses need to understand what the internet can actually see, not only what internal design documents say should be visible. Real exposure review often catches the difference between intention and reality. It shows when an asset is public, which services respond, how reputation signals look, whether administrative paths remain reachable, whether supporting services are visible, and where the business may have assumed the provider was covering risks that in fact remain customer responsibilities.
Where Front Screen fits
This is exactly the gap Front Screen is designed to help close. Businesses and enterprises often do not need another abstract reminder that cloud security is shared. They need practical external checks that show where weaknesses and exposures may already exist. They need a way to review publicly reachable services without depending on every internal team having specialist knowledge of internet-facing risk.
Front Screen helps organisations offload a meaningful part of that visibility work. It gives teams a way to check what their cloud-hosted assets look like from the outside and to identify weaknesses before they become incidents, outages, or expensive remediation projects. That is valuable for smaller businesses without a dedicated security function, and it is equally useful for larger environments where cloud complexity grows faster than manual review can keep up.
Well-known cloud providers remain an important part of modern infrastructure, and using them is often the right decision. The risk is not the provider itself. The risk is assuming that provider-managed infrastructure automatically means customer-managed exposure has already been secured. It rarely has. The safer approach is to treat every public cloud endpoint as something that still deserves deliberate review, hardening, and external visibility testing.